리눅스에서 어떤 파일의 내용 중 원하는 내용만 추출하기 위해 grep, sed 등의 명령어를 사용합니다. 이와 더불어 더 나아가 좀 더 복잡하고 다양한 패턴을 적용하여 데이터를 추출하는 데에는 awk 명령어를 사용하는 경우가 많습니다.
awk 명령어의 기본적인 사용 방법
리눅스에서 사용하는 awk 명령어는 (awk Programming Language)라고도 불리며, 다른 명령어들과는 다르게 프로그램 형태로 있습니다.
즉, awk 명령어를 사용하는 것은 awk 라는 프로그램을 실행시키는 것과 같습니다.
awk 명령어를 사용하면, awk 프로그램을 이용하여 텍스트 형태로 되어 있는 어떤 파일의 내용을 행과 단어별로 처리하여 원하는 데이터를 추출할 수 있습니다.
awk 명령어는 여러 종류의 함수를 사용할 수 있지만 이 글에서는 입출력 함수 중 하나인 print 함수를 사용하여 awk명령어의 기본적인 사용 방법을 다루고자 합니다.
awk 명령어의 동작 원리
awk를 사용하여 파일의 내용을 편집하기 위해서는 awk 명령어를 사용했을 때 어떤 방식으로 텍스트를 구분하는지 파악해야 합니다.
awk 명령어 프로그램에서는 텍스트 파일의 데이터를 레코드와 필드로 구분합니다.
※ 레코드 (Record)
awk 명령어는 먼저 파일의 텍스트를 행 (가로) 단위로 가져옵니다. → 행 하나를 하나의 레코드 라고 부릅니다.
※ 필드 (Field)
가져온 하나의 행에 있는 텍스트 들을 공백 단위로 구분합니다. → 구분된 텍스트들은 필드 라고 부릅니다.
※ awk 명령어 동작 순서
- awk 명령어를 통해 해당 텍스트 파일을 레코드 (행) 단위로 읽어옴
- 읽어온 레코드가 원하는 패턴에 맞는 레코드인지 확인
- 레코드에 원하는 패턴 적용
- 패턴이 적용된 후 출력 내용 결정 (해당 레코드 전체를 출력할 것인지 ($0), 특정 필드(열)만 출력할 것인지 ($1~$99))
하나의 행 (레코드)은 여러 개의 단어 (필드)로 구성되어 있으며, awk 명령어 사용 시 먼저 하나의 행 에 있는 각각의 필드만 따로 출력하거나, 패턴을 적용하여 출력할 수 있습니다.
레코드는 awk 명령어 사용 시 $0 (행 전체) 로 사용할 수 있으며, 그 레코드 안에 각 필드 들은 가장 왼쪽 텍스트부터 공백을 기준으로 $1, $2 ... $99 로 사용할 수 있습니다.
awk 명령어 사용 예시
]# awk '[패턴]' [파일명]
]# cat [파일명] | awk '[패턴]'
awk 명령어 또한 grep, sed 등 다른 명령어와 마찬가지로 파이프라인 ( | )을 통해 중복 사용 및 다른 명령어와 같이 사용하는 것이 가능합니다.
※ 기본적인 awk 명령어 예시
| 명령어 예시 | 설명 (test.txt 파일에서 ~) |
| awk '{print $0}' test.txt | 파일 전체 출력 |
| awk '{print $3}' test.txt | 각 행 에서 3번 필드만 출력 |
| awk '{print $1,$5}' test.txt | 각 행 에서 1번, 5번 필드만 출력 |
| awk '{print $3"님"}' test.txt | 각 행에서 3번 필드에 "님" 이라는 텍스트를 붙여서 출력 |
| awk '$2==40 {print $0}' test.txt | 2번 필드가 40인 경우 해당 행 전체 출력 |
| awk '$2==40 {print $3}' test.txt | 2번 필드가 40인 경우 해당 행의 3번 필드만 출력 |
| awk '/aaa/ {print $3}' test.txt | aaa 문자가 들어간 행에서 3번 필드만 출력 (특수문자는 \ (역슬러쉬) 혹은 달러표시로 사용 가능) |
| awk '$3 ~/aaa/ {print $0}' test.txt | 3번 필드에 aaa 문자가 들어간 행만 출력 |
| awk '!x[$1]++ {print $0}' test.txt | 1번 필드를 기준으로 중복되는 행 제거 후 남은 행 출력 |
원본 파일 file_1.txt 내용 확인

]$ cat [파일명]
= 해당 파일 내용 확인
]$ awk '{print $0}' [파일명]
= 해당 파일 내용 중 파일 전체 ($0 사용) 출력
awk 명령어를 예시로 사용해보기 위해 원본파일 file_1.txt 내용을 먼저 확인해보려고 합니다.
기본적으로 cat 명령어를 사용해서 파일 내용을 확인해보았으며, awk 명령어에서 파일 전체 내용을 출력해주는 패턴을 사용하여 해당 파일의 내용을 확인했을 때, cat 명령어의 출력문과 동일한 결과를 확인할 수 있습니다.
1. 각 행에서 특정 필드만 출력

]$ awk '{print $4}'
]$ awk '{print $5}'
= 각 레코드에서 4번 혹은 5번 필드만 출력
awk 명령어의 패턴이 구분하는 방식에서 필드는 공백을 기준으로 구분하기 때문에 각 레코드 (행)들은 서로 다른 개수의 필드를 가지고 있을 수 있습니다.
원본파일 file_1.txt 에서도 확인해보면 1번, 2번, 11번 레코드 (행)은 5개의 필드 ($1 ~ $5)를 가지고 있습니다.
반면, 3번 ~ 10번 레코드는 7개의 필드 ($1 ~ $7)를 가지고 있습니다.
awk 명령어를 사용하여 특정 필드만 출력하는 패턴을 사용하는 경우, 각 레코드에서 개별적으로 해당 위치의 필드를 찾아 출력하게 됩니다.
2. 각 행에서 두 개 이상의 열 출력
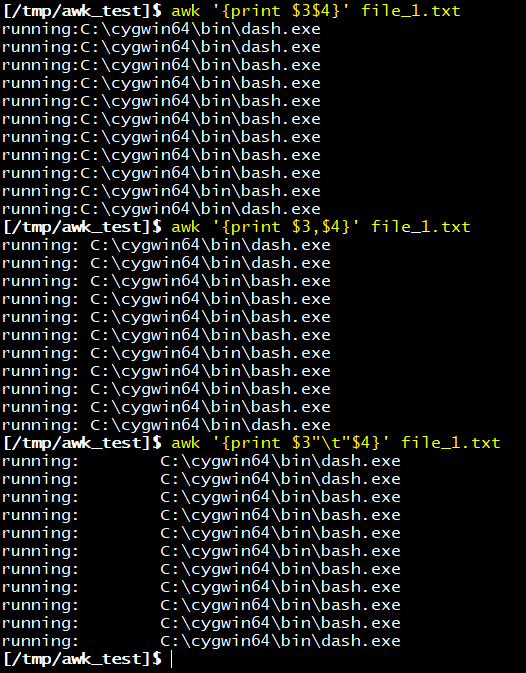
]$ awk '{print $3$4}'
]$ awk '{print $3,$4}'
]$ awk '{print $3"\t"$4}'
= 해당 파일에서 3번, 4번 필드 (열) 출력
awk 명령어의 패턴은 해당 파일에서 레코드들이 가지고 있는 필드의 개수가 동일한 경우 내용을 열 (세로) 단위로 관리하기 편리합니다.
파일에서 원하는 열 여러개를 따로 출력하고 싶다면 해당 위치에 맞는 필드 ($1~$99)를 입력하여 여러개의 필드 출력이 가능합니다.
여기서 여러개의 필드(열)을 출력하고 싶을 때, 출력되는 필드를 무엇으로 구분할 지 선택할 수 있습니다.
※ awk '{print $3$4}'
= 출력되는 필드들을 구분 없이 하나로 합쳐서 출력
※ awk '{print $3,$4}'
= 출력되는 필드를 쉼표(,)를 사용하여 각 필드 사이에 공백(space)으로 구분되어 출력
※ awk '{print $3"\t"$4}'
= 출력되는 필드를 \t를 사용하여 각 필드 사이에 tab으로 구분되어 출력
3. 필드에 원하는 텍스트를 추가하여 출력
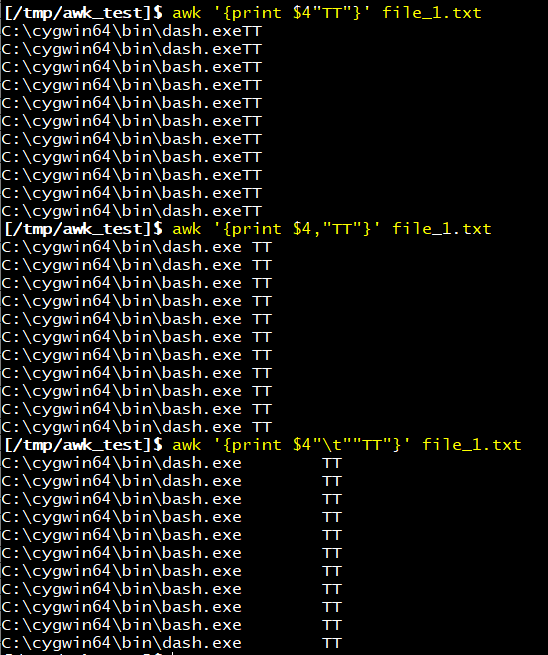
]$ awk '{print $4"TT"}'
]$ awk '{print $4,"TT"}'
]$ awk '{print $4"\t""TT"}'
= 4번행에 TT 텍스트 추가하여 출력
awk 명령어에서 원하는 위치의 필드를 출력하는 것 뿐만 아니라 해당 필드 앞,뒤에 원하는 텍스트를 추가할 수 있습니다.
파일에서 4번 필드를 찾아 출력하고, 4번필드 뒤에 각각 필드구분자 (쉼표, \t)를 사용하여 "TT"라는 문자를 추가하여 출력하였습니다.
※ awk '{print "텍스트"$1~$99"텍스트"}'
= 필드 앞, 뒤에 원하는 텍스트를 추가하여 출력
텍스트를 추가할 때는 쌍따옴표 (" ")를 사용하여 추가할 수 있으며 해당 필드 앞,뒤에 원하는 위치에 추가하여 사용할 수 있습니다.
4. 필드 구분기호 변경하기
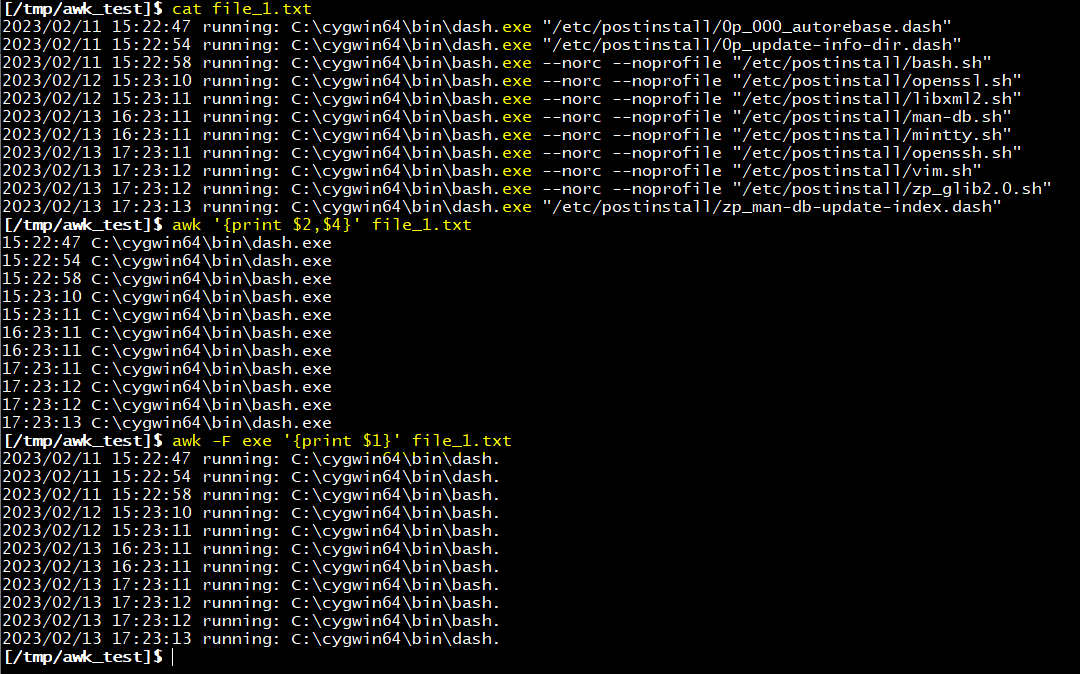
]$ awk -F exe '{print $1}'
= 필드구분기호를 exe로 변경하여 1번 필드 출력
awk 명령어의 print 함수에서 필드를 ($1 ~ $99) 출력할 때, 기본적으로 필드번호는 공백을 기준으로 부여되어 출력합니다.
여기서 -F 옵션을 사용하면 기본 default 값이였던 공백을 → 다른 문자로 바꾸어 필드번호를 구분하여 출력할 수 있습니다.
awk '{print $2,$4}' 에서는 공백을 기준으로 각 레코드(행) 에서 2번, 4번필드(열)이 출력되는 것을 확인할 수 있습니다.
awk -F exe '{print $1}' 에서는 -F 옵션을 사용하여 필드의 구분기호를 공백 → "exe"로 변경하였습니다. 그에 맞게 각 필드를 exe로 구분하여 1번 레코드 (exe 문자 앞쪽 전체) 가 출력되는것을 알 수 있습니다.
※ awk -F 구분기호 '{print $1~$99}'
= 레코드에서 원하는 문자로 구분기호를 지정하여 그에 맞게 필드번호가 부여됨
5. 레코드에 숫자 패턴을 사용한 출력 (비교연산자)
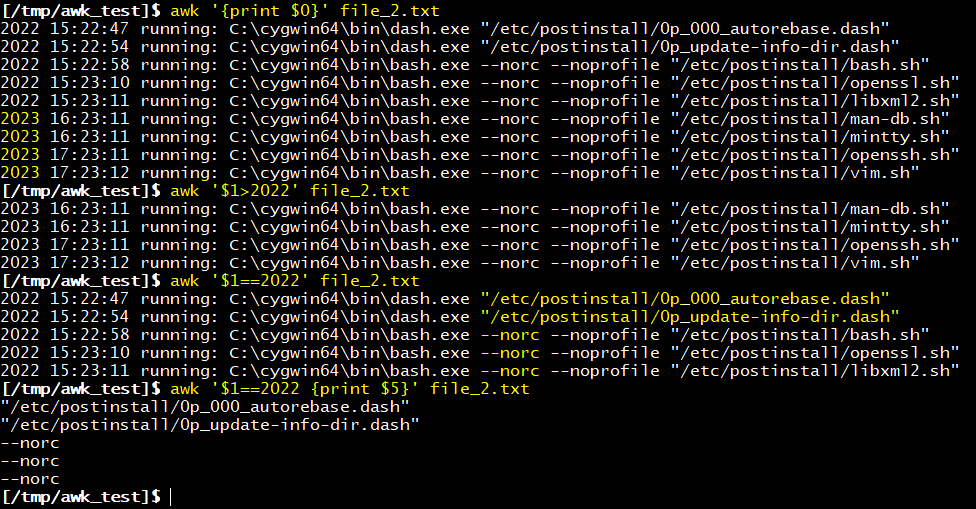
]$ awk '$1>2022'
= 1번 필드가 2022보다 큰 경우 출력
]$ awk '$1==2022'
= 1번 필드가 2022와 같은 경우 출력
비교연산자를 사용한 awk 출력문 입니다. 숫자를 사용하여 특정 필드가 원하는 값보다 크고 작은 경우를 구분하여 출력할 수 있습니다.
print 함수 앞에 특정 필드에 원하는 비교연산자를 사용하여 해당 패턴에 맞는 레코드만 출력할 수 있습니다. 여기서 print 함수를 이용해 패턴에 맞는 레코드의 특정 필드만 출력할 수 있습니다.
※ 비교연산자 (>, >=, <, <=, !=, ==)
$1 > 100 : 1번 필드가 100보다 큰 경우
$1 >= 100 : 1번 필드가 100보다 크거나 같은 경우
$1 < 100 : 1번 필드가 100보다 작은 경우
$1 <= 100 : 1번 필드가 100보다 작거나 같은 경우
$1 == 100 : 1번 필드가 100인 경우
$1 != 100 : 1번 필드가 100이 아닌 경우
※ awk '$1==2022 {print $1~$99}' [파일명]
= 해당 파일에서 1번 필드가 2022와 같은 레코드를 찾아, 원하는 필드번호를 출력
6. 레코드에 문자 패턴을 사용한 출력 (패턴 연산자)

]$ awk '/--norc/ {print $7}'
= "--norc"문자가 있는 레코드 중 7번필드만 출력
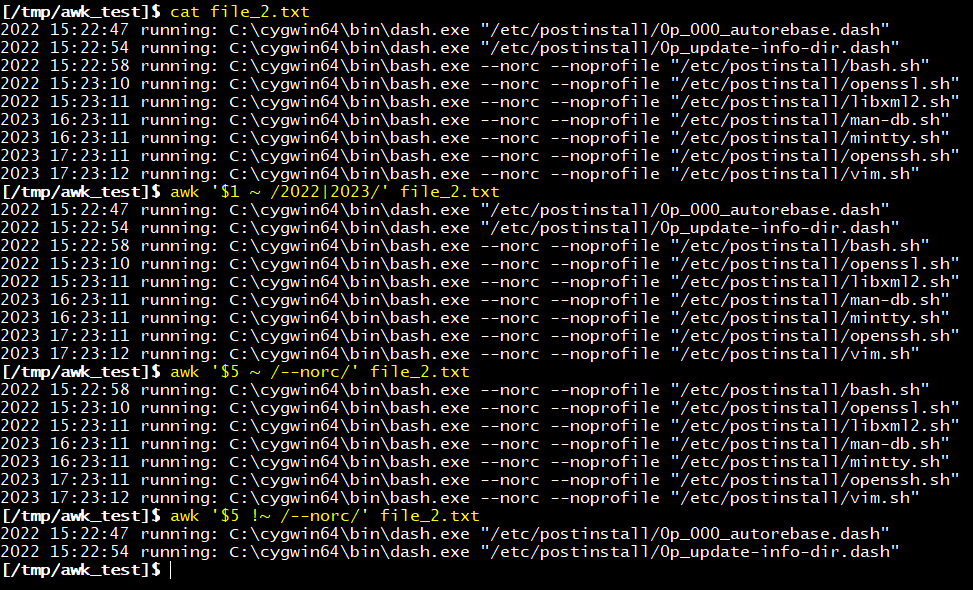
]$ awk '$1 ~ /2022|2023/'
= 1번 필드에 2022 혹은 2023 문자가 포함된 레코드만 출력
]$ awk '$5 !~ /--norc/'
= 5번 필드에 "--norc"문자가 없는 레코드만 출력
레코드에서 특정 문자열이 포함된 레코드를 출력하고 싶을 때 슬러쉬 (/)를 사용해 해당 문자를 패턴으로 사용할 수 있습니다.
'/문자열/' 형식으로 사용하면 해당 문자열이 포함된 레코드를 출력할 수 있으며, 패턴연산자를 사용해 '$1 ~ /문자열/' 형식으로 특정 필드에 해당 문자열이 있는 레코드만 출력하는 것도 가능합니다.
여러개의 문자열 패턴은 파이프라인을 사용하여 적용할 수 있습니다.
※ awk '/문자열/'
= 특정 문자열이 포함된 레코드만 출력 (특수문자의 경우 역슬러쉬 (\) 혹은 달러표시를 붙여서 사용)
※ awk '/문자열1|문자열2/'
= 파이프라인 (|)을 사용해 문자열 두 개 출력 (문자열1 or 문자열2 중 한 가지만 포함되더라도 해당 레코드 출력)
(파이프라인 : [Shift] + \)
※ awk '$1 ~ /문자열/'
= 1번 필드에 특정 문자열이 포함된 레코드만 출력 (패턴연산자 ~ : 해당 문자와 같은 경우)
※ awk '$1 !~ /문자열/ {print $1~$99}'
= 1번 필드에 특정 문자열이 포함되지 않은 레코드 중, 원하는 필드 출력 (패턴연산자 !~ : 해당 문자와 같지 않은 경우)
'개인 > 리눅스' 카테고리의 다른 글
| [리눅스] sed 명령어의 기본적인 사용방법 두번째 (0) | 2023.05.03 |
|---|---|
| [리눅스] sed 명령어의 기본적인 사용방법 (1) | 2022.10.18 |
| [리눅스]for 문 한줄로 사용하기 (0) | 2020.04.29 |
| [리눅스] grep 명령어의 기본적인 사용방법 (0) | 2020.03.22 |
| [리눅스] VNC란? 사용목적과 설치 (0) | 2020.02.29 |